
在某些情况下,系统导出的序时账 或 客户提供的序时账由于业务体量较大,公司组织架构庞杂,其文件数量及数据规模都会很大,比如某一期间的序时账,混杂.xlsx, .xls, .csv格式的Excel工作簿合计超过1,500份,按照平均每个文件夹100-200左右份文件的情况,散布在10个左右不同文件夹中。
文件夹及内含文件、格式情况举例如下:
实务中,Excel总大小接近10GB,合计内容行数远超100万行(超过Excel单表行数上限),使用Power Query或者VBA进行并表十分耗时,于是考虑使用Python来抓取:1.位于特定位置的一组多个文件夹中;2.格式可以为.xlsx, .xls, .csv;3.工作簿内含的序时账抬头列可能顺序不同,但有统一抬头比如“科目名称”、“科目编码”等的一组文件中,包含某个科目编码或者名称字段的所有行信息。
运行示例1. 选取目标文件夹

运行示例2. 选取列名 & 包含字符(比如科目编码),并确认CSV编码格式
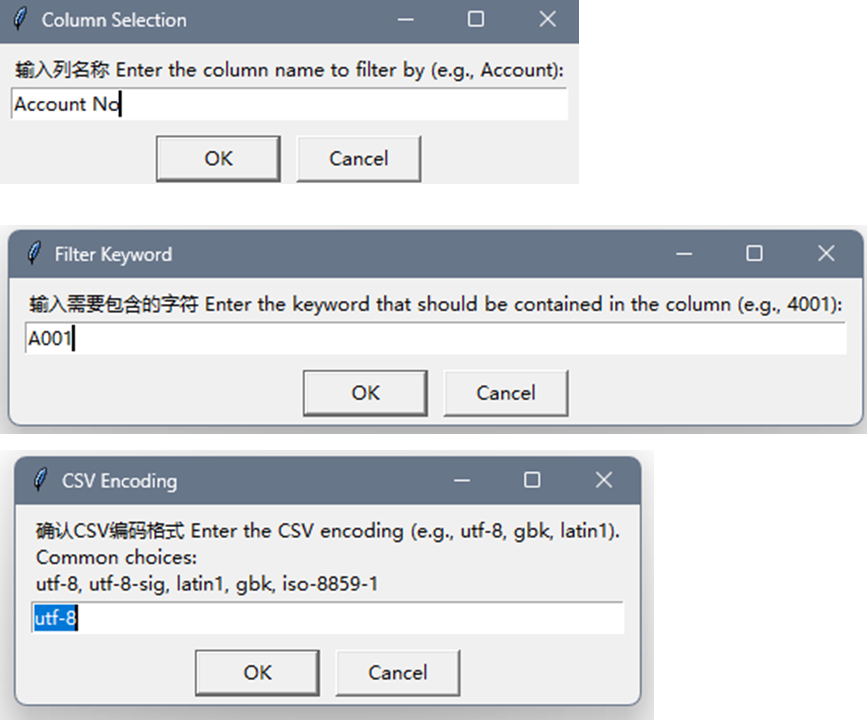
运行示例3. 确认保存位置 & 新文件名称

运行示例4. IDLE Shell 运行并完成提取
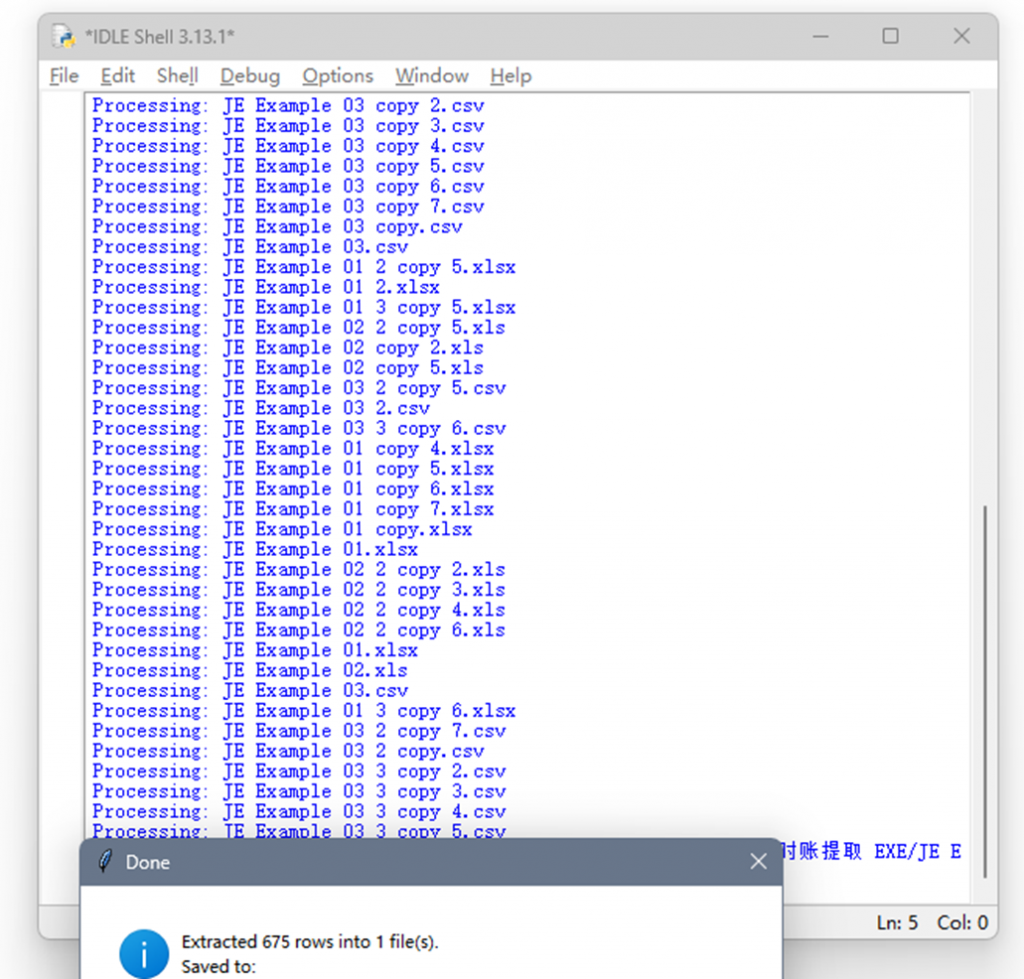
运行示例5. 打开新文件,可见其已经提取了相应Account No下编码为A001的全部分录行

如下为可实现上述功能的Python代码:
import os
import pandas as pd
from glob import glob
from tkinter import Tk, filedialog, simpledialog, messagebox
# --- GUI setup ---
root = Tk()
root.withdraw()
folder_path = filedialog.askdirectory(title="选择包含表格的主文件夹 Select the main folder with files")
if not folder_path:
messagebox.showerror("Error", "No folder selected. Exiting.")
exit()
column_name = simpledialog.askstring("Column Selection", "输入列名称 Enter the column name to filter by (e.g., Account):")
if not column_name:
messagebox.showerror("Error", "No column name entered. Exiting.")
exit()
keyword = simpledialog.askstring("Filter Keyword", "输入需要包含的字符 Enter the keyword that should be contained in the column (e.g., 4001):")
if not keyword:
messagebox.showerror("Error", "No keyword entered. Exiting.")
exit()
# --- 确定 CSV Encoding ---
encoding_choices = ["utf-8", "utf-8-sig", "latin1", "gbk", "iso-8859-1"]
encoding_default = "utf-8"
encoding_input = simpledialog.askstring(
"CSV Encoding",
f"确认CSV编码格式 Enter the CSV encoding (e.g., utf-8, gbk, latin1).\nCommon choices:\n{', '.join(encoding_choices)}",
initialvalue=encoding_default
)
if not encoding_input:
messagebox.showerror("Error", "No encoding selected. Exiting.")
exit()
csv_encoding = encoding_input.strip().lower()
# --- Output location & filename ---
output_path = filedialog.asksaveasfilename(
title="确认新文件存储位置 Select where to save the output Excel",
defaultextension=".xlsx",
filetypes=[("Excel files", "*.xlsx")]
)
if not output_path:
messagebox.showerror("Error", "No output file selected. Exiting.")
exit()
# --- Collect files ---
all_files = []
for root_dir, _, files in os.walk(folder_path):
for file in files:
if file.endswith(('.xlsx', '.xls', '.csv')):
all_files.append(os.path.join(root_dir, file))
print(f"Found {len(all_files)} files...")
# --- Process files ---
filtered_rows = []
def load_and_filter(file_path):
ext = os.path.splitext(file_path)[1].lower()
try:
if ext == '.xlsx':
df = pd.read_excel(file_path, engine='openpyxl')
elif ext == '.xls':
df = pd.read_excel(file_path, engine='xlrd')
elif ext == '.csv':
df = pd.read_csv(file_path, encoding=csv_encoding)
else:
return pd.DataFrame()
# Normalize column names
df.columns = [col.strip().lower() for col in df.columns]
search_col = column_name.strip().lower()
if search_col not in df.columns:
print(f"Column '{column_name}' not found in {file_path}")
return pd.DataFrame()
# 模糊匹配(包含关键字)
filtered_df = df[df[search_col].astype(str).str.contains(keyword, case=False, na=False)]
return filtered_df
except Exception as e:
print(f"Error in {file_path}: {e}")
return pd.DataFrame()
for file in all_files:
print(f"Processing: {os.path.basename(file)}")
df = load_and_filter(file)
if not df.empty:
filtered_rows.append(df)
if not filtered_rows:
messagebox.showinfo("Result", f"No entries found for '{keyword}' in column '{column_name}'")
exit()
combined_df = pd.concat(filtered_rows, ignore_index=True)
# --- 导出 Export ---
ROWS_PER_FILE = 1_000_000
total_rows = len(combined_df)
num_files = (total_rows // ROWS_PER_FILE) + 1
base_name, ext = os.path.splitext(output_path)
for i in range(num_files):
start = i * ROWS_PER_FILE
end = min(start + ROWS_PER_FILE, total_rows)
part = combined_df.iloc[start:end]
part_file = f"{base_name}_Part{i+1}{ext}"
part.to_excel(part_file, index=False, engine='xlsxwriter')
print(f"Saved: {part_file} ({len(part)} rows)")
messagebox.showinfo("已完成 Done", f"Extracted {total_rows} rows into {num_files} file(s).\nSaved to:\n{base_name}_Part*.xlsx")注意,上述需要使用 IDLE 3.13来运行,并且需要确保您的系统中已经预装了相应Python功能。
开发内容较为简单,实际操作中如出现进一步需求或者问题,欢迎一起讨论!